

Ice Lake架构深度解析 Intel的雅典娜女神
Ice Lake是Intel下一代平台的架构代号,随着台北电脑展上的演示,它终于揭下来神秘的面纱。而前不久Intel内部的第二季度财报会议上,CEO已经宣布Ice Lake处理器已经正式向OEM厂商出货,戴尔方面也迅速行动,延期了一个月多的、采用新Ice Lake处理器的XPS 13 7390也迅速上架接受预定并将于近日发货。这意味着Intel的第一代量产级10nm产品(不算Cannon Lake唯一的那款10nm i3)终于要在市场上亮相了,在此之际,小编编译、整理了目前有关于Ice Lake架构的相关解析文章,探寻其背后的改进之处。
继上一次Intel更新他们的桌面级处理器的架构已经过去了将近5年的时间了,不得不说,Skylake是一代非常成功的架构,也可能是从P6以来Intel使用时间最长的一代处理器架构,支撑Intel走到现在还在主流和服务器市场上面占据着上风。
首先我们要理清一点,Ice Lake是整个处理器架构的代号,而现在的Intel处理器架构中包括了内核、GPU、以及Uncore部分的其他IO单元,所以本文并不只是针对CPU的内核微架构进行解析,而是对于整个体系结构。
注:如果没有说明来源,本文图片均来自于WikiChip和AnandTech。

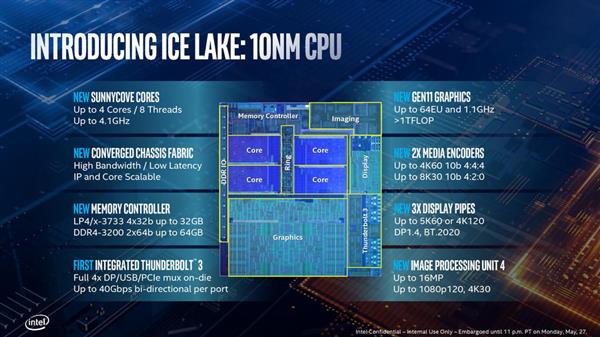
Ice Lake处理器结构图Sunny Cove内核微架构:IPC平均提升18%

Sunny Cove内核结构图前端缓冲区:加大加大加大
x86处理器的内核主要可以简单地分成两个部分,前端部分与后端执行部分,前端部分主要完成“取指译码”的工作,后端主要为指令的具体执行单元,前后端之间有缓冲区,用于存放解译融合完毕的微指令。Intel很早就在内核中引入了“微指令融合”的技术来提高效率,融合过的微指令会进入缓冲区然后被分配给后端执行部分进行具体的执行。Intel目前认为,如今程序更多的瓶颈位于访存和前端指令分派上,Sunny Cove的前端部分改进就体现了这一理念,所以这次缓冲区就被扩大了不少。
缓冲区部分对比架构HaswellSkylakeIce Lake乱序重排缓冲区192224352访存Load队列大小7272128访存Store队列大小425672超 能 网 制 作
可以看到Intel这次把乱序重排缓冲区(ReOrder Buffer,主要是用于乱序执行后将执行的微指令根据原本顺序提交的指令缓冲区)大小做到了可以容纳352条微指令,直接提升了128条/57%之多,而Haswell到Skylake才仅仅提升了32条。同样在访存上面也进行了不小的提升,Load(加载)队列增加了56,Store(存储)队列增加了16,比Haswell到Skylake的改变都明显要多。
缓存对比架构HaswellSkylakeIce Lake单核心一级数据缓存大小32KB32KB48KB单核心一级指令缓存大小32KB32KB32KB单核心二级缓存大小256KB256KB512KB微指令缓存1.5K μOPS1.5K μOPS2.25K μOPS超 能 网 制 作
再来看缓存部分,新的内核终于增加了万年没变动过的一级数据缓存,从32KB到48KB,虽然只增加了12KB,但是要知道,32KB的一级指令缓存+32KB的一级数据缓存的设计,从Core系列的第一代架构——Core微架构上面就开始使用了,一直沿用到现在,同时一级数据缓存的带宽也增加了。而每个内核附带的二级缓存直接提升一倍,达到512KB的大小,这也是从Nehalem架构把二级缓存内置进每个核心、单独设立共享L3缓存以来在内核缓存上发生的最大幅度变动了。

Skylake与Sunny Cove内核架构对比图,左Skylake,右Sunny Cove
前端部分的改进较小,主要是改进了预取器与分支预测器的性能,增加了微指令缓存的大小使得其能够满足每周期5(6)指令的发射。
后端:更宽

上Skylake,下Icelake,注意看Port
后端也有不小的改变,Sunny Cove的执行端口相比Skylake多了两个,达到了10个之多。并且端口的用途更为精细化,有专门用于读取和存储地址的端口,并且专用于存取数据的端口数量均为两个。

然后在执行单元中,Sunny Cove新增了支持AVX-512指令的单元,其实这类单元在Skylake-Server上便已经加入,同时引入的还有Cannon Lake上面加入的iDIV这个硬件整数除法器,同时还加入了新的MulHi单元,专用于乘法指令的处理。
AVX-512计算单元的引入使得Sunny Cove内核一次可以处理1条512-bit的指令或者2个256-bit的指令。
内核互联方面,桌面级Ice Lake仍将采用Ringbus也就是环形总线的设计,而服务器端将延续Skylake-Server的Mesh总线设计。
指令集与AI加速
指令集随着新单元的加入也同时进行了扩充,在加密解密、AI加速、通用计算、特定计算等方面都新加入了不少指令,尤其是AVX-512指令集。
对于近几年大热门的人工智能,Intel一方面在Uncore部分加入了自家的“高斯网络加速器(Gaussian Network Accelerator)”这样类似于手机SoC上面常见的AI硬件加速电路,还通过引入AVX512VNNI指令集,使用AVX-512单元来进行AI相关的加速计算,Intel将这种加速称为"DL(Deep Learning) Boost"。这是一种很聪明的取巧办法,专用计算单元的引入可以保证一定的加速性能,而新指令集的加入同时也可以更加充分地利用上新的CPU特性。
加密解密指令集上面的改动诸如AES的吞吐量加大、加入新的针对SHA算法的一系列指令等,总之在编译器进行适当优化的前提下,Ice Lake的加密解密性能是比Skylake强不少的。
小结
简单归纳一下Sunny Cove微架构的改进点:
改进了预取器与分支预测器的性能
一级数据缓存增大50%
一级缓存存储带宽增大100%
二级缓存增大100%
微指令缓存增大50%
每周期能够加进乱序重排缓冲区的微指令多了25%
乱序重排缓冲区大了57%
后端执行端口多了25%
支持AVX-512等新指令集
综合以上的改进,Sunny Cove相对于Skylake在IPC上面取得了平均18%的进步,而对于Broadwell或者说Haswell,则是有47%的进步幅度,在针对AVX-512进行优化过的测试中,最高可以比上代移动低压处理器快2~2.5倍。在摩尔定律前进缓慢的今天,这个数字已经非常高了。
题外话,其实很多改进在Cannon Lake上面就已经有了,比如AVX-512、相关的指令集变动和缓存带宽增加等,还有些改动是从Skylake-Server架构上面下放而来的,比如AI加速的指令集其实已经在服务器端处理器上出现了。但因为Cannon Lake实际被Intel放弃,所以继承了Cannon Lake改进点的Sunny Cove内核架构才能在相比较Skylake时得到平均18%的IPC进步,如果一切正常,Intel的10nm没有延期,Ice Lake应该是Cannon Lake的下一代,对比起来就没那么大的进步幅度了。
第11代图形架构
Ice Lake的核显首次达到了1TFlops的计算性能,还增加了不少的功能特性,可谓改进颇多。Intel用了"the most powerful version"来形容这代核显的性能,怎么做到的呢?

借助10nm工艺,暴力堆叠规模
Intel的10nm工艺在晶体管密度上的提升幅度是真的很大,14nm时代最多配备24组EU的核显,在Ice Lake上面直接就翻了2.67倍,最大可以达到64组EU,并且频率也不低,最高可以跑到1100MHz,比以前只低了50MHz,此时核显整体的FP32计算量已经达到了1.15TFlops。鉴于此,相比于八代酷睿处理器上搭载的第9代核显,Intel官方宣称可以提供平均约1.8倍的帧率。

你一定想问第10代去哪里了对不对,其实还是在夭折了的Cannon Lake上面,而且唯一一颗的核显还是被屏蔽了的。
目前在移动低压版Ice Lake处理器上面,Intel一共提供了G1、G4和G7三种配置的核显,分别有32/48/64组EU,低端的G1命名仍为"UHD",而G4和G7都以"Iris Plus"的品牌出现。
除了通过制程进步来堆叠EU数量之外,内部架构的优化也同样重要。
内部架构优化

与第九代核显的对比表格如图,出处:周末杂谈,Icelake CPU的助手,Gen11核显简介
首先通过增加单个Slice中含有的子Slice来扩大规模,使得每周期的计算次数增加。
其次是在缓存系统上做文章,扩大了三级缓存的容量,Intel方面公布的是EU的三级缓存有3MB,并且还有0.5MB的本地共享内存。另外还有通过处理器的内存控制器升级,能够用上更高的内存带宽。
新接口版本和加强的硬件编码电路
上个月让小编最难受的一件事情就是买了一台1440p,144Hz刷新率的显示器,用HDMI连接笔记本的时候,在1440p下面最高只能输出60Hz,究其原因,就是老的第9代核显支持的HDMI版本只能到1.4,最高只能提供4K@30Hz的输出,1080p下面最大是120Hz,而小编的笔记本并没有提供USB-C或者DP输出。
而Ice Lake终于解决了这个痛点,支持了HDMI 2.0b和DP 1.4 HBR3,这两个就不用多说了吧,反正就是最高分辨率和帧数提升顺便还能支持一下HDR。
另外,在视频硬件编码部分,也就是Intel QuickSync特性使用的独立硬件电路上,新核显也有比较大的改进,现在支持两条HEVC 10-bit同时进行编码,在YUV444的情况下最高支持两条4K60帧视频流,或者一条YUV422的8K30帧视频流。
可变速率着色(VRS)
VRS全称Variable Rate Shading,是一种新的允许GPU根据画面区域的重要性调整着色精度的技术,具体效果我们之前的新闻有介绍过,可以看一下:来对比一下VRS可变速率着色技术带来的性能提升吧 3DMark将添加该技术基准测试一文中的图片对比。

VRS可以在不重要的画面上面节约一定的GPU资源,使这部分GPU资源参与更加重要的部分画面的渲染中,从而提高了整体的帧数,目前NVIDIA已经在Turing核心中加入了相关的支持。而Intel也没有落后,在第11代核显中提供了这项特性,并且他们宣布将与Epic合作,将这项特性加入到虚幻引擎中去,目前文明六已经支持了该技术,并且根据Intel的数据,帧数最大提高了30%。
小结
GPU部分的改进主要还是规模增加了很多,架构上属于小改动,主要改进了缓存系统,不过第11代核显的进步还是比较明显的。

可能以后在1080p低画质下面核显也不再是鸡肋了,能够30帧打打游戏了。
Uncore部分
Uncore部分指的是处理器上除了内核和GPU的其他部分,在顶上的结构示意图中就是System Agent的那部分,自从Intel在Nehalem把内存控制器和PCI-E控制器移入CPU内部之后就没有什么大的变化,但是这次Intel在上面加入了个新东西,还升级了不少老部件。
Thunderblot 3
原来阻挡人们使用Thunderblot(以下简称TB)设备的一大原因就是这个接口的使用成本略高,当TB3开始以USB Type-C接口的形式出现之后,使用率确实高上去不少,但是还有其他的拦路虎,其中一个就是TB需要主板搭载额外的芯片来使用,这个控制芯片并不便宜。终于在Ice Lake上面,Intel把TB控制器整合到了处理器里面,并且再也不会占据掉处理器提供的PCI-E总线数量或者是与PCH一起挤原本就已经拥挤不堪的DMI 3.0总线,而是在环形总线上面拥有了自己的位置。
而且Intel大方的一下子就提供了4个之多的TB3接口,每个都是PCI-E 3.0 x4的满规格,也就是说,Ice Lake处理器其实一共拥有32条PCI-E 3.0通道,不过其中一半都是以TB3形式提供的,当然这些接口是支持USB模式的,当运行于USB 2.0状态时,会绕回到PCH上进行通信。
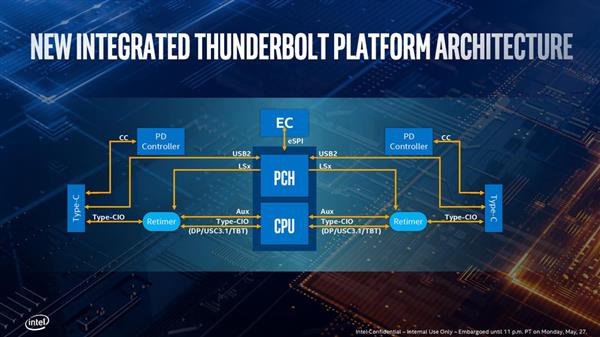
当然也不是所有的厂商都会给足四个TB3接口,具体怎么配置还是得看OEM厂商,毕竟其他的配套芯片诸如USB PD所需要的独立IC都是会增加成本的,而TB接口还需要额外的Retimer芯片,不过Intel已经减半了所需的Retimer,两条TB3只需要1个Retimer就可以了。
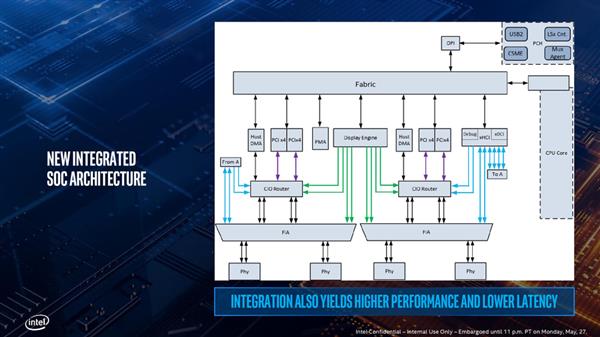
不过将TB控制器集成到CPU内部也使得整个System Agent的IO部分更为复杂了,上面是一张详细的原理图,一个Type-CIO路由(图上名为CIO Router)拥有两条PCI-E 3.0 x4与CPU相连,而CPU内部的显示控制引擎(图上的Display Engine)也要与这个Type-CIO路由相连,以控制Type-C接口所处的状态,并决定发送的信号。同时还有USB的xHCI也要跟Type-CIO连接,还要管理整个的内存统一性……
复杂的结构所导致的就是整体的延迟会增加,Intel将原因归结在电源控制上面,原本分离式的芯片很容易管理电源状态,但是整合进来之后每一个部分都有自己的电源状态需要管理,需要更为精细化的电源管理系统,而这就增加了总体的延迟。不过更为精细化的电源管理还是有好处的,那就是可以提高能耗效率,Intel方面称满载的一个TB3接口的芯片外加链路层将使用300mW的功率,四个加起来也只有1.2W。
值得一提的是,Intel已经做好了对于USB4的兼容,不过考虑到目前USB4仍处于草案阶段,不排除未来的修改使得兼容失效。不过目前只是针对Ice Lake的移动版本进行架构分析,当然也不排除Intel在桌面级的Ice Lake上面同样保留内部TB控制器。
题外话,TB3据说在Cannon Lake上面也是有的,但是夭折了。
内存控制器
现在内存控制器原生支持DDR4 3200/LPDDR4X 3733内存,原来Skylake上面的内存控制器顶多只能支持到DDR4 2666,还是八代的Coffee Lake以后的事情了。而随着DDR4内存的发展,默频上3000的内存条也开始出现了,内存控制器直接支持到DDR4 3200是一件不错的事情。而且随着处理器内核数量的增加,内存带宽也逐渐要开始成为处理器性能的一个瓶颈所在了,在我们的测试中,内存带宽对于游戏性能的影响还是比较明显的。
此前Intel的移动低压平台只能使用LPDDR3作为内存,而支持LPDDR4/X的一个好处就是可以在更低的功耗下面带来更强的性能,尤其是对于此次图形性能有比较大提升的Ice Lake来说,有着非常大的实际意义,因为内存带宽直接影响到GPU的实际表现。
GNA
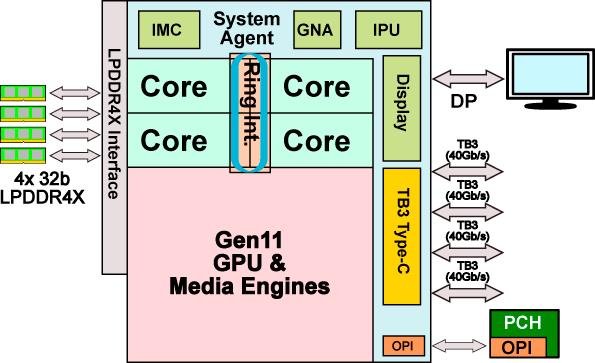
前面在讲内核的AI加速时提到了Uncore部分加入了GNA这个针对AI的硬件加速单元,目前并不知道太多有关于它的细节,就连具体名字都有两种说法,在Intel官方针对Windows Machine Learning的介绍网页中,它的全名为Gaussian Network Accelerator,而在很多介绍Ice Lake架构的文章中,它的名字又成了Gaussian Neural Accelerator。
目前已知的是该单元的功耗非常低,甚至会在SoC其余部分关闭的情况下继续工作,旨在提供稳定的AI加速性能,应用场景为语音识别之类。
图像处理单元
Ice Lake上面的图像处理单元(Image Process Unit)升级到了第4代,是的,你大概没有听说过Intel的CPU上面还有个图像处理单元,但它从Skylake开始就一直存在,不过只有在移动双核型号上有,属于DSP(数字信号处理器)范畴,为设备的相机提供影像处理功能。
Ice Lake上的IPU可以提供4K@30fps的视频拍摄能力,还有更好的硬件降噪能力,支持更多的相机,还支持将两个不同的相机比如一个抓IR信息一个抓RGB信息的两个相机模拟成一个设备来看待。
Intel方面称,他们正在向软件开放更多的IPU寄存器,以向应用提供更好的便利性,并且提供了对机器学习的支持。另外值得一提的是,Intel将之前PCH上集成的MIPI接口转移到了CPU上,未来可以用于接驳AI加速设备。
小结
Uncore部分可谓是发生了天翻地覆的改变,可以说是Ice Lake相对于之前Skylake变化最大的地方了,内建TB3控制器肯定会给未来的使用带来非常大的方便,小编个人非常喜欢这个改进。而其他的可以归于常规性质的功能性更新。
PCH改进
目前的Ice Lake平台上PCH和CPU是封装在同一块基板上的,PCH的提升同样是Ice Lake整个平台的提升。同样的,Ice Lake CPU通过DMI 3.0 x4总线与PCH相连,提供的带宽等同于PCI-E 3.0 x4。
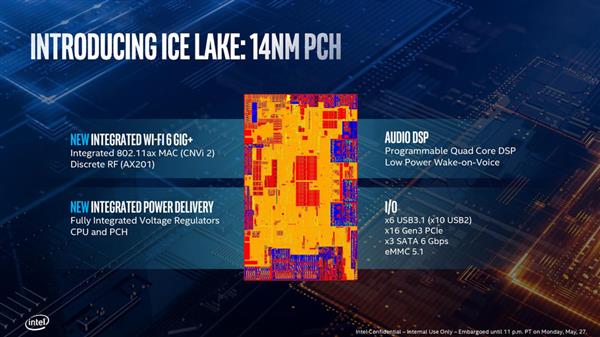
重新引入FIVR
FIVR其实早在Haswell架构中就已经被引入了,但是从Skylake开始又把它给去掉了,因为在当时FIVR确实表现不佳,导致了整体功耗和发热的增大。不过在Ice Lake上面,它又回归到了CPU和PCH的内部。Intel官方表示这么做可以节约整个平台的面积,并且简化OEM的电源设计。新的FIVR有着更高的电源效率,与整个平台的节能特性息息相关。看上去Intel也是解决了FIVR身上的一些毛病才放心将它集成进CPU和PCH内部的。
CNVi 2
其实Intel在这两年已经在出货的芯片组里面都加入了CNVi方案的Wi-Fi模块,这种方案将Wi-Fi网卡的部分电路转移到了芯片组的内部,而仍在外面充当一个射频模块的Wi-Fi网卡就可以做的非常小了,比如M.2 2230或者以1216规格直接焊在主板上。PCH内部的网卡与在外面的RF模块通过一条Intel专有的CNVi链路进行连接。
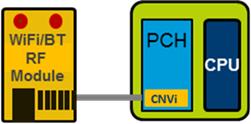
Ice Lake的PCH上面这条特别的CNVi链路升级到了第二个版本,即CNVi 2。

当然,支持的Wi-Fi标准还是由在外面的Wi-Fi网卡所决定的,方便OEM自定义,Intel此举是为了打破人们升级Wi-Fi路上的屏障(你倒是推动一下AX路由器降价啊),目前Intel有两张支持Wi-Fi 6标准的无线网卡:AX200/201。
关于Wi-Fi 6具体的提升之处,可以参考我们之前的文章:超能课堂(188) WiFi 6凭什么可以如此“六”?。
IO
这块就简单罗列一下数据。
6个USB 3.1(5Gbps)/10个USB 2.0
16条PCI-E 3.0,一般会有8条用于两个NVMe接口
3个SATA 3.0
eMMC 5.1
Intel没有提到UFS的支持。
小结
PCH的变化并不是很大,主要是常规的功能性提升。
封装、睿频与功耗多种功耗目标与不同封装方式
目前Ice Lake-U和Ice Lake-Y是两种目标TDP不同的系列,分别针对15~28W和7~12W来设计的,未来的移动标压级TDP约为45W,而桌面级目前未知。

此次率先发布的11款低压和超低压也采取了两种不同的封装,U系列没有怎么变,还是老样子,而超低压就与往常不一样了,Intel使用了更加紧凑的封装方式,同时底部触点也相对更加紧密。

动态调节 2.0
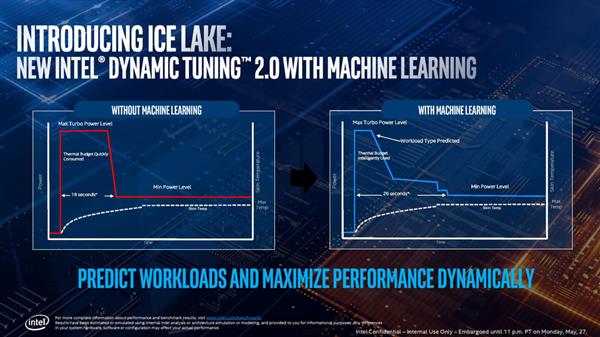
新的动态调节2.0技术变化点看图就可以了,大致意思就是Ice Lake处理器不会像之前那样只能睿频18秒之后就回到基础频率,而是慢慢的降下来,整个过程比原先长了8秒。新技术还使用了机器学习来预测CPU将会吃到哪种类型的负载,然后智能调节功耗预算来尽可能地延长睿频时间。
总结
总的来看,Ice Lake是一代变化非常大的架构,无论是内核还是外面的各种组件。人们都说Intel挤牙膏,但怎么说呢,竞争对手所给的压力不够也是Intel挤牙膏的一个原因,但更多的原因恐怕是来自于这几年Intel在制程工艺上面遇到的难题,本来在Intel的Tick-Tock战略中,Cannon Lake是作为Skylake的制程升级版出现的,然而由于10nm的难产,Tick-Tock战略彻底失效,变成了PAO——制程-架构-优化战略之后,计划以10nm初代的角色推出,结果10nm比PAO战略的计划还要晚,但是竞争对手的Zen和Zen+架构开始给Intel压力了,没办法,Skylake加两个核用14nm++再顶一顶吧。这一顶就是将近两年过去了,Cannon Lake也被彻底的放弃了,上面的许多优化被Ice Lake所继承了下来。
从整体架构来看,Ice Lake在单线程性能上面继续冲高,而测试成绩也都印证了这一点:基础频率和加速频率都比前代更低的情况下单线程成绩能够将将打平,已经很不容易了。多核的话,Ringbus极限应该是十核左右,如果不采用Mesh架构,那么桌面版未来的Intel Ice Lake处理器还是会不敌AMD的Zen 2/3。
而在扩展性上面,Ice Lake还是比较良心的,TB3控制器的加入使得USB和TB设备不再需要挤占原本就有些不够的PCI-E 3.0总线,并且还预留了与USB4的兼容,在未来Ice Lake的优化版或者升级版上我们有望看到正式的USB 4支持。
Ice Lake也会是未来一段时间中Intel主力的架构,只不过等它来到桌面级还需要一段时间。Intel目前的产品线也是非常的混乱,有机会我们会单开一篇文章来捋一捋。