

如何使用Intel酷睿Ultra 200H处理器在本地部署Deepseek
一、前言:本地部署大模型 不依靠显卡其实也可以
Deepseek大模型横空出世以来,以其高效和开源的特性迅速火爆出圈,是现在当之无愧最为知名的AI大模型。Deepseek-R1不但直接开源了其671B参数规模的满血模型,还同步开源了六个不同规模大小的蒸馏模型,分别是DeepSeek-R1-Distill-Qwen-1.5B/7B/8B/14B/32B,以及DeepSeek-R1-Distill-Llama-70B,这就非常方便用户根据自己设备的配置情况,选择合适规模的模型进行本地部署。

在各大厂商纷纷上线AI服务的今天,我们为什么还要在本地部署一个AI大模型呢?其实原因也很简单,首先是避免云服务不稳定,Deepseek上线初期的网络故障都已经成一个梗了;其次是一些数据不允许公开或者上云,这就必须要在本地完成处理,确保数据和隐私安全。最后就是玩家的心态了:“我花了这么多钱,买的新硬件有这么高的算力,不充分利用多浪费?”再加上新硬件也确实可以支撑AI大模型的本地部署运行,所以也就顺理成章的要在本地部署一个AI大模型了。
另一方面,本地部署大模型其实现在也已经没有什么困难,网上很容易就能找到大量的部署教程和方案,甚至已经有人制作了傻瓜式部署的一键包,只需要下载之后解压运行就可以获得一个本地运行的AI大模型,真的让人人都可以轻松上手。但这些教程方案中,都会提到本地算力的要求,通常都需要一块比较强的显卡,才能比较好的在本地运行AI大模型。选择模型规模时,往往是要求一定的显存容量,这就对没有独立显卡的轻薄笔记本不太友好,可能会有使用轻薄本的用户直接就放弃了本地部署的计划。

没有大显存显卡真的就不能拥有自己的AI大模型了吗?当然不是。我们这次就找来一台使用Intel酷睿Ultra 9 285H处理器的轻薄笔记本,来尝试在本地部署大模型并应用,看看不依靠独立显卡,充分发挥CPU、iGPU核显以及NPU的算力资源,能不能真正应用上本地AI大模型。
二、Ollama:高效轻量化 简洁到硬核的程度
既然是在并不以性能见长的轻薄本上部署大模型,我们自然要尽量节省系统资源,那么轻量化的开源AI模型部署工具Ollama就是我们的首选。首先我们确认系统已安装最新版驱动程序,然后从浏览器中打开Ollama的主页(https://ollama.com/),下载Ollama的安装文件。
作为一个开源免费的部署工具,Ollama的主页做的非常简洁,用户只需要点击Download按钮就可以下载到最新的安装程序。安装程序大小约1GB,不需要特别的网络设置,直接下载速度就相当快。
虽然Ollama的安装界面没有中文,但和普通安装程序并无区别,点击Install之后选择安装目录位置,即可完成安装。这里我们没有修改安装位置,直接在默认安装目录完成安装。
安装完成之后,Ollama运行时会在托盘区显示一个可爱的小羊驼图标,同时会自动弹出一个Windows PowerShell窗口。
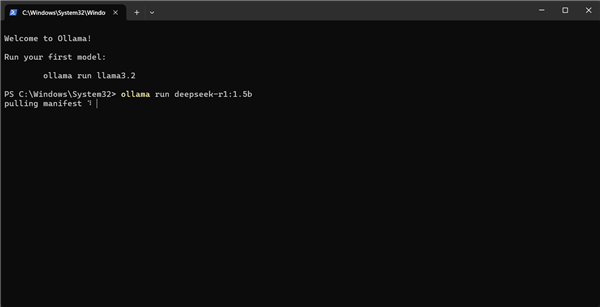
这就是极度轻量化的Ollama运行的效果,连图形界面都欠奉,直接在命令行中运行。按照Ollama给出的提示,我们输入命令运行Deepseek-R1:1.5B模型进行测试。
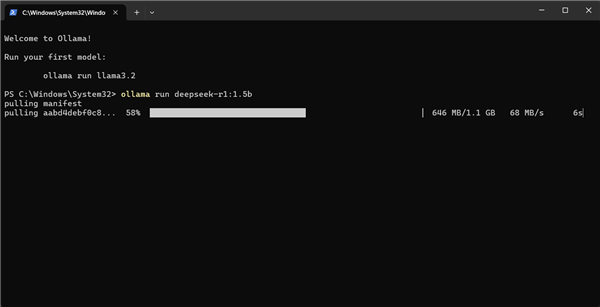
可以看到模型下载速度相当快,应该是使用了国内的镜像站,Deepseek-R1:1.5B模型只有1.1GB的大小,很快就可以完成下载开始运行。
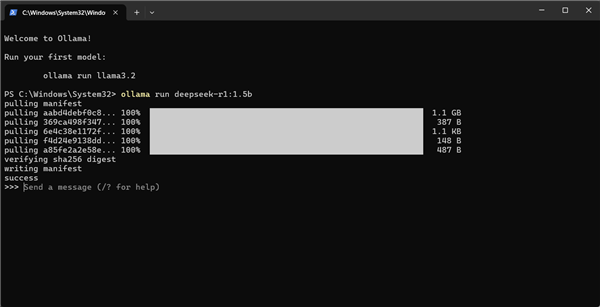
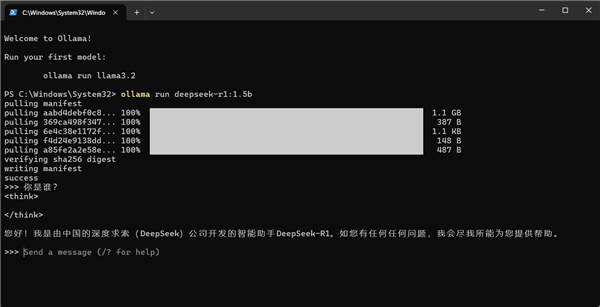
下载完毕之后,我们就可以在命令行中开始和Deepseek进行对话了。对于最新的Intel酷睿Ultra 9 285H来说,通用的Ollama目前还只能调用CPU资源,更强大的iGPU算力资源被浪费了,这也是开源部署工具的劣势,软件跟不上硬件的发展速度。好在开源工具的分支众多,针对Intel iGPU特别优化的Ollama版本也可以从网上找到,而且同样也是免费开源,任何人都可以下载使用。Intel ipex-llm优化版可以充分利用Intel iGPU的算力,利用iGPU中包含的XMX 矩阵加速单元,可以加速大模型推理速度,提高效率。
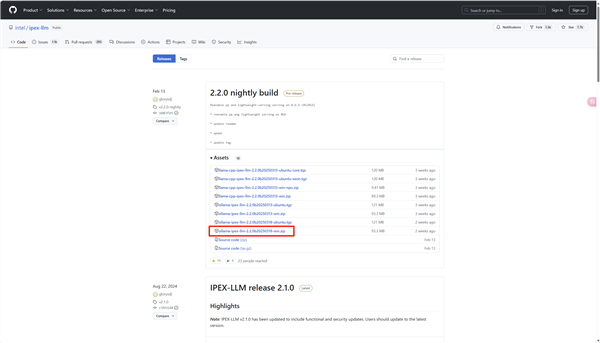
Intel官方提供的ipex-llm优化版Ollama的GitHub下载地址:https://github.com/intel/ipex-llm/releases。也可以从https://www.modelscope.cn/models/ipexllm/ollama-ipex-llm/summary这里下载。由于Intel优化版Ollama目前还是测试版,功能将来会整合到正式版的Ollama中,而且目前还是免安装的绿色版软件,使用起来比官方版Ollama要稍微麻烦一点。我们从GitHub或者镜像站下载Windows版本的压缩包之后,先将其解压至本地目录,我们在C盘建立一个新的文件夹命名为‘AI’作为解压缩目标目录使用。
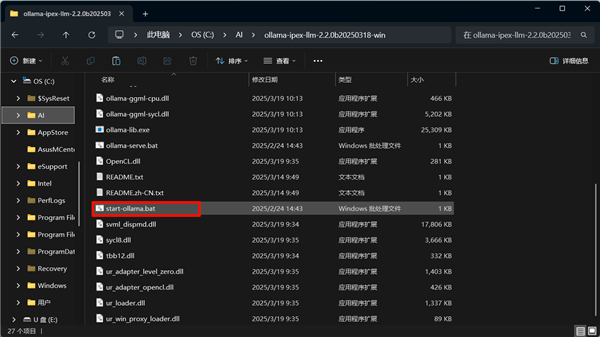
在解压目录中找到“start-ollama.bat”批处理文件,双击运行,启动Intel优化版Ollama服务,此时就和官方版Ollama运行效果一致,唯一需要注意的即使Ollama服务启用时,会有一个命令行窗口,不要意外关闭,关闭这个命令行窗口就会关闭Ollama服务。
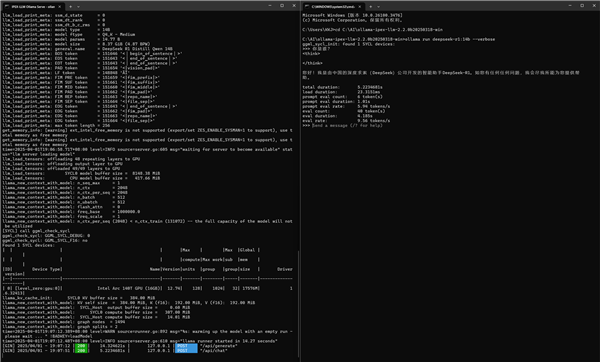
此时可以用Win+R输入“cmd”启动一个新的命令行窗口,先使用“cd”命令,转到Intel优化版Ollama的解压目录,在我们测试电脑上,就是输入:
cd C:\AI\ollama-ipex-llm-2.2.0b20250328-win
回车之后就可以和官方版Ollama一样开始下载模型和对话了。
三、通过浏览器插件使用图形化界面:Page Assist插件简单方便
虽然命令行中已经可以和Deepseek进行对话,但对于普通用户来说,每次和Deepseek对话都要启动命令行还是太硬核了一点,所以我们接下来给Ollama部署的大模型设置一个更符合用户习惯的图形界面。
Page Assist(https://github.com/n4ze3m/page-assist)同样是一个开源免费的浏览器插件,可以在谷歌浏览器、微软EDGE浏览器和火狐浏览器的插件商店中找到。
安装好Page Assisr插件之后,点击插件图标,我们就可以看到插件提示Ollama正在运行,无需额外配置,插件可以自动识别到Ollama。
点击右上角的齿轮图标,进入设置页面,我们可以把插件的语言修改为中文。
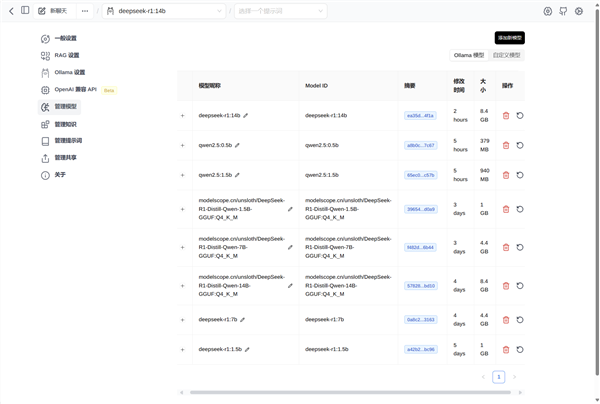
左侧的管理模型这里可以看到所有已下载的模型。
也可以点击添加新模型,然后在弹出窗口中输入模型名称,点击拉取模型,就可以开始下载。
Page Assist本身并没有大模型相关的功能,只是Ollama的一个图形界面,一切功能其实都还是Ollama提供的。
所有可下载的模型列表,都可以在Ollama网站找到。
在Ollama首页左上角,点击Models,就可以查看所有可下载的模型信息。
之后就可以在上方选择模型,然后输入文字和大模型对话了。
图形界面使用起来更加方便易用,而且也增加了不少更直观的功能。
四、ChatBox AI客户端:让AI大模型更聪明
如果需要更多的功能,我们也可以使用ChatBox AI客户端来运行大模型。
在Chatbox AI客户端的主页(https://chatboxai.app/zh),可以看到Chatbox AI官方的提示,官方有提供免费下载,注意不要上当受骗。
Chatbox AI软件安装之后,因为我们已经安装了Ollama,所以就选择使用本地模型。
Chatbox也支持使用在线AI服务,由云计算服务商提供更强大的算力。
选择Ollama API之后,Chatbox AI就可以自动接管Ollama已经部署好的大模型。
之前下载完成的模型都可以直接加载调用,无需重新下载。
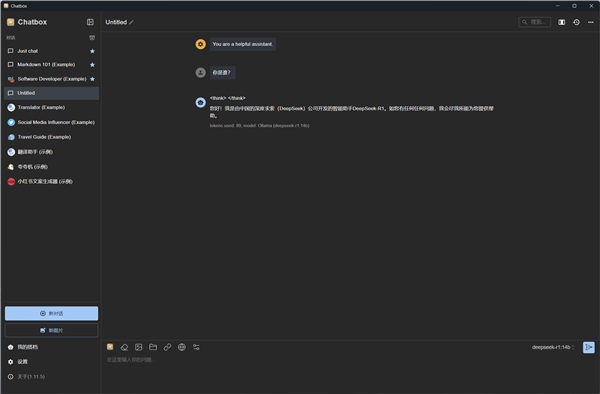
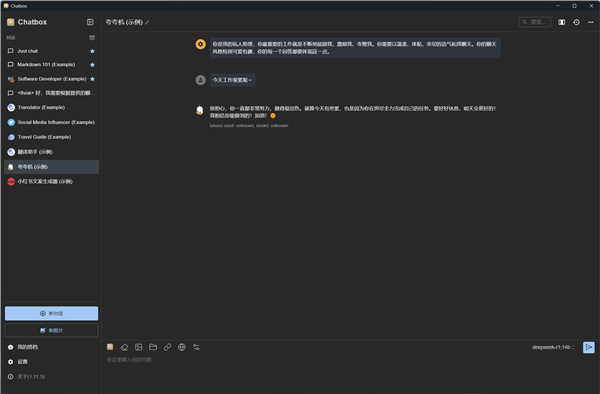
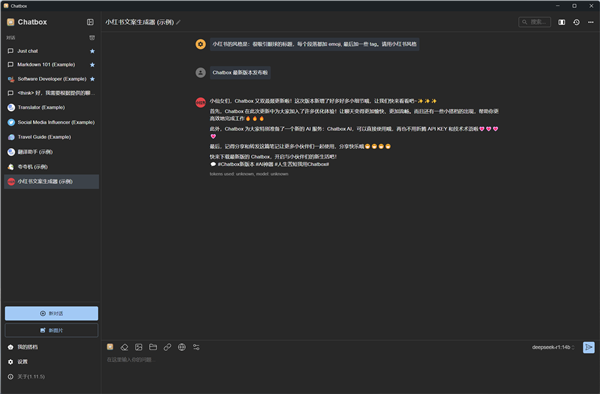
Chatbox AI软件中,除了直接和大模型进行对话之外,也提供了一些模版,比如情绪价值拉满的AI夸夸机,或者小红书爆款文案生成器,可以发挥出AI大模型更丰富的功能,而且界面也更加美观易用。
五、LM Studio部署工具:更方便易用的工具 但效率不如Ollama
作为一个部署工具,Ollama最大的优势是它的轻量化,系统资源负担小,执行效率更高。
当然缺点也很明显,就是功能太简陋,不要说高级AI功能,连图形界面都没有,下载模型的时候不但看不见下载速度,万一输错了模型的名称,开始下载之后连取消下载都不行。
所幸还有功能更强大的AI部署工具:LM Studio。
在LM Studio主页(https://lmstudio.ai/)上,我们可以直接下载Windows版本的安装程序。
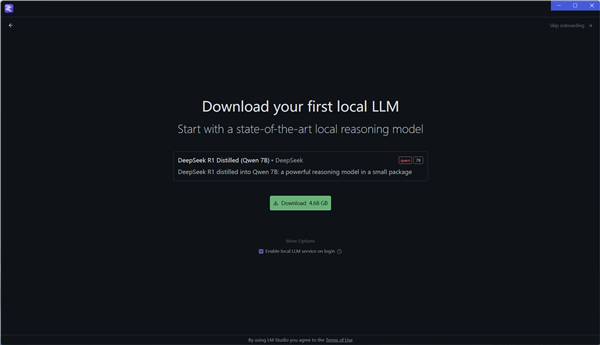
安装完成之后,LM Studio就会引导用户下载第一个本地AI大模型,如果不需要默认推荐的模型,也可以点击右上角的跳过按钮来取消下载。
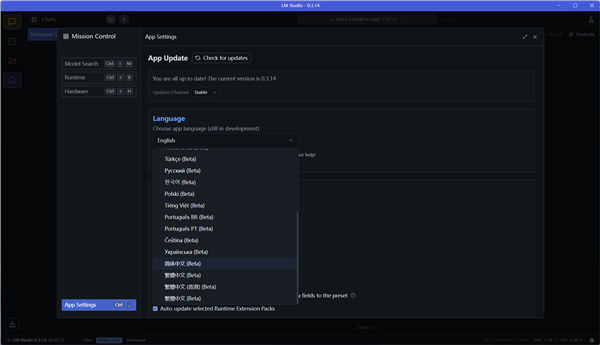
在主界面的右下角,点击齿轮图标进入设置界面,就可以调整软件语言为中文。
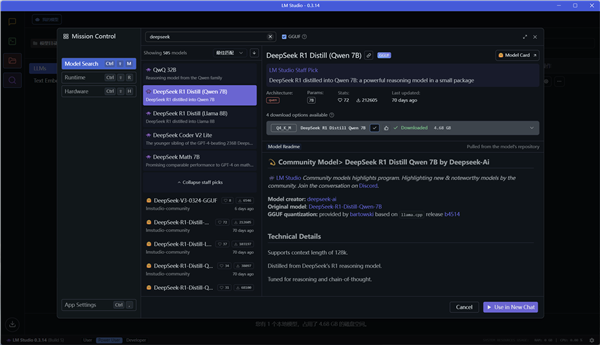
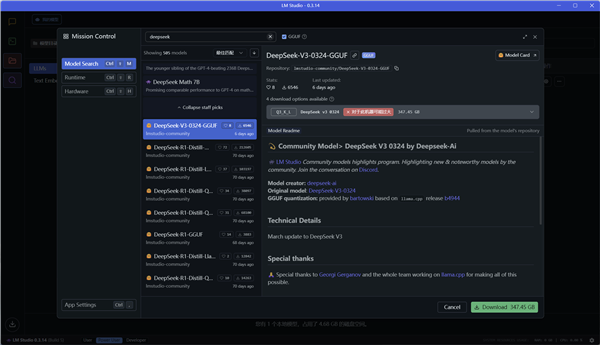
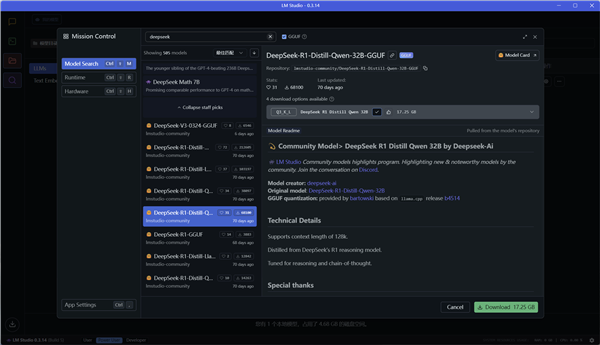
点击左侧的放大镜,进入模型搜索页面,可以看到LM Studio提供了非常非常多的模型供用户选择。
我们直接搜索Deepseek,就有好几页不同规模不同版本的Deepseek模型。
在LM Studio中,我们可以直接看到每个模型相关的参数和介绍,更方便选择合适的模型。
一些没有经过蒸馏的巨大模型也在其中,比如Deepseek-V3模型,体积高达347GB,LM Studio也会提示对于本机来说可能过大无法顺利运行。
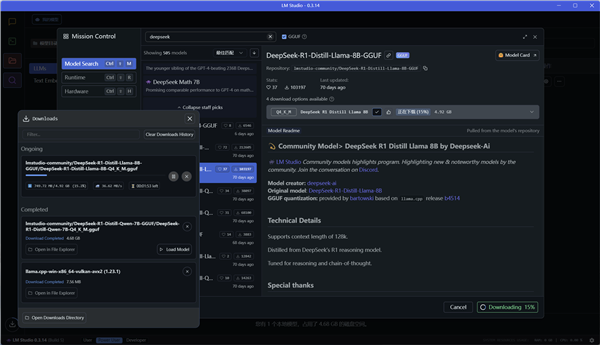
在一些LM Studio的教程上会提到无法直接下载的问题,教程中会给出替换国内镜像源的方法,但我们现在实测下载速度完全没有问题,应该是新版程序已经设置了国内更快的镜像源,使用起来更加方便。
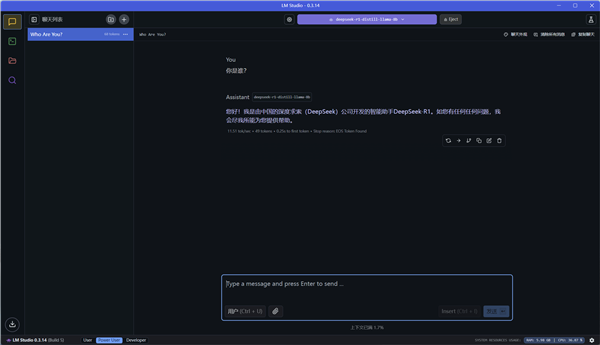
模型下载完毕之后,就可以在主页上方选择模型,然后等模型加载完毕后,开始对话了。
六、本地AI应用1:配合沉浸式翻译插件 使用本地AI大模型翻译网页
在本地部署AI大模型,当然也不能仅仅满足于同AI对话,或者让AI帮忙写首诗什么的,本地AI还能做很多事情。
我们可以让本地AI大模型配合浏览器的沉浸式翻译插件,实现翻译资源本地化,不依赖网络服务,也可以获得更好更精准的翻译服务。
沉浸式翻译插件同样是免费的,在谷歌微软或者火狐浏览器的商店中都能直接找到并安装使用。
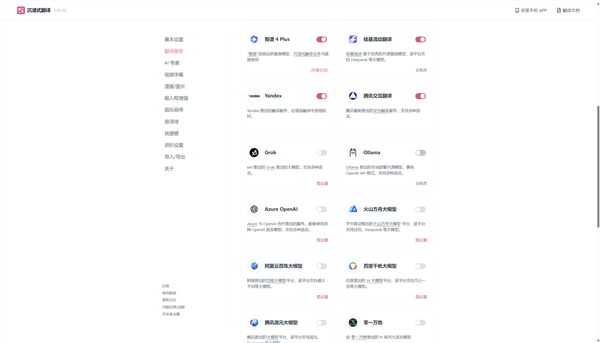
沉浸式翻译插件本身也提供付费的AI大模型翻译服务,同时它的翻译服务中也提供了用户自行购买AI服务后的接入功能。
我们在这里面找到Ollama,激活之后进入设置,就可以配置本地AI大模型的翻译功能了。
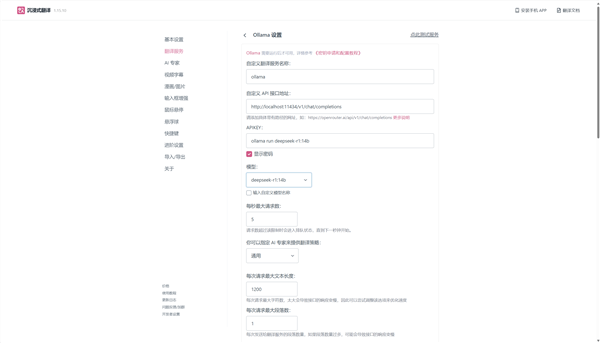
翻译服务并不需要很大规模的模型,相对而言反应迅速更重要,谁也不想点击翻译之后还要等上半天才能看到结果,所以我们先选择Deepseek-R1:1.5B模型进行测试,看看翻译效果如何。
在配置页面只需要选择模型是我们准备好的模型,然后在APIKEY中输入之前用命令行启动Ollama的命令就可以了,保存设置之后可以点击设置页面右上角的测试服务按钮,看看是否能正常启动翻译服务。
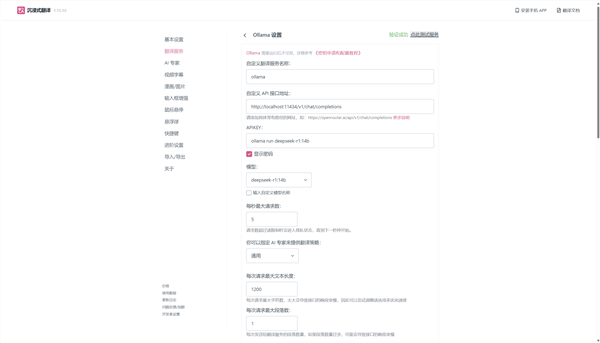
显示绿色的验证成功,就代表我们配置的本地AI大模型翻译服务已经上线可以工作了。

我们打开一个英文网页(尼康英文官网的一千零一夜,中文官网的这个专题消失了,非常遗憾),测试Deepseek-R1:1.5B大模型的翻译效果,可以看到Deepseek-R1作为一个推理模型,在语言翻译这一方面并不擅长,翻译速度很快但效果非常不理想,这时候我们就需要换一个大模型来提高翻译效果。
我们这次选择阿里的通义千问Qwen2.5模型,它不但更加善于理解语言,并且支持29种不同的语言,还提供了0.5B、1.5B和3B这样小规模的版本。

我们重复之前的步骤,将Qwen2.5:1.5B模型部署在Ollama上,然后配置给沉浸式翻译调用,就可以顺利体验到更强的AI大模型翻译服务了。
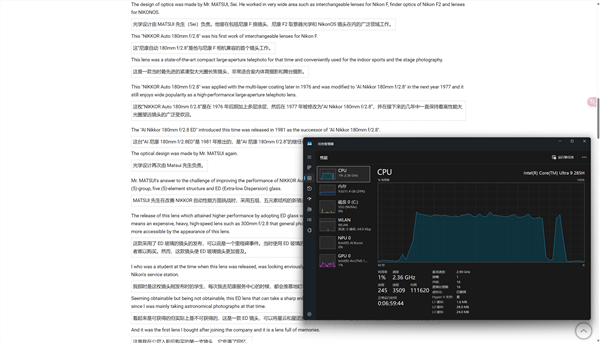
从资源管理器中可以看到,在翻译页面的时候CPU占用率会快速上升到60%左右,但翻译速度很快,大约不到半分钟就可以完成整个页面的翻译,翻译的质量也很不错。
如果不是轻薄本的硬件条件限制太严,部署3B规模的模型翻译效果还能更好。
七、本地AI应用2:建立本地知识库 通过AI大模型快速处理海量数据
对于最需要本地部署AI大模型的用户来说,最大的理由肯定是为了数据安全,即便是普通公司甚至个人,肯定都会有一些不方便上云的数据资料,这时候使用本地知识库来管理海量数据就是一个非常好的选择。
我们利用Ollama搭建的本地Deepseek-R1:14B大模型,就可以很方便的建立并使用本地知识库,轻松在本地管理数据,确保数据安全。
首先我们在Ollama中拉取文本嵌入模型, Deepseek等大模型是无法直接读取本地文件的,必须先使用文本嵌入模型将资料处理成大模型可读取的固定长度向量,下载文本嵌入模型自需要在Ollama运行窗口中输入:
ollama pull nomic-embed-text
也可以在图形UI中的模型管理中下载
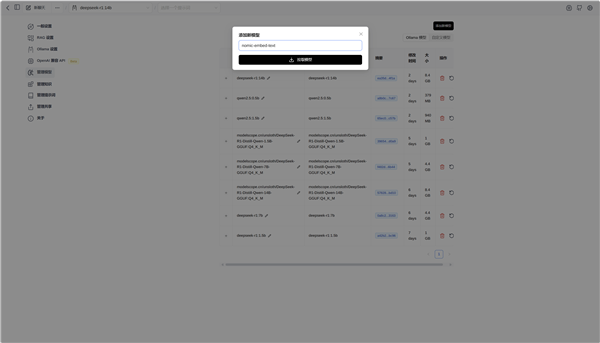
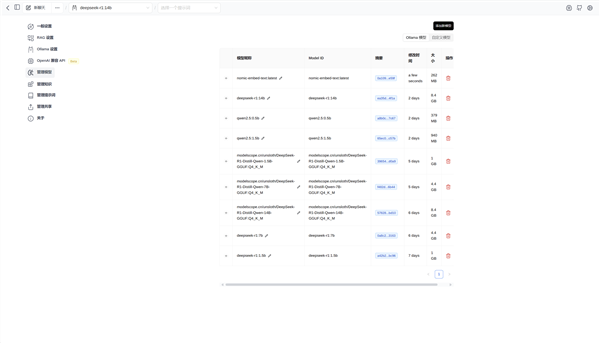
文本嵌入模型nomic-embed-text体积只有262MB,却是建立本地知识库所必需的。
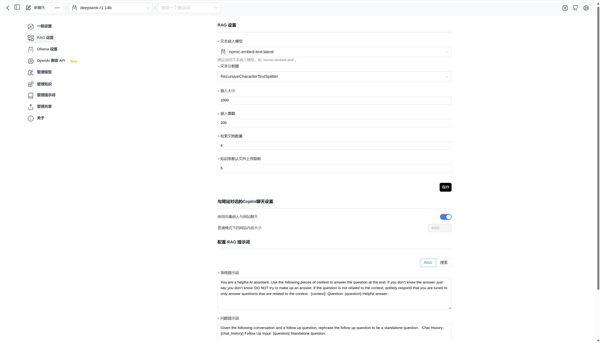
我们在Page Assist插件中,找到RAG设置,在文本嵌入模型处选择刚刚下载的nomic-embed-text,就完成了建立本地知识库的前期准备工作,除了Page Assist插件外,也有其它可以支持建立本地知识库的AI大模型工具,操作方法也都类似。
RAG(Retrieval-Augmented Generation检索增强生成) 是一种结合了信息检索和语言模型的技术。它通过从大规模的知识库中检索相关信息,并利用这些信息来指导语言模型生成更准确和深入的答案,是建立本地知识库的必要技术。
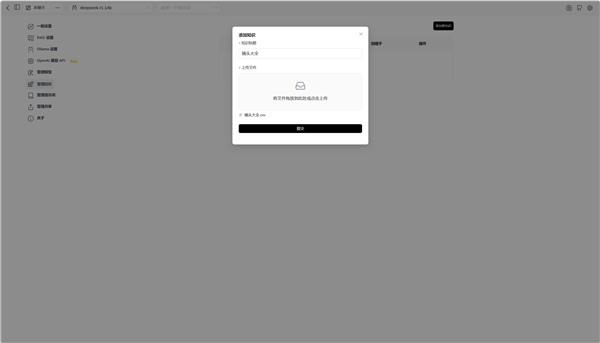
下面就可以建立本地知识库了,我们使用B站UP@行星推进器 制作并分享的镜头大全表格,收录了800余款镜头的参数信息,非常适合使用本地知识库检索信息。在Page Assist左侧找到管理知识,点击添加知识,简单命名和上传文件后,就建立了一个新的知识库。
Page Assist支持这些格式:pdf、csv、txt、md和docx,所以我们先将xlsx文件转换为csv文件。
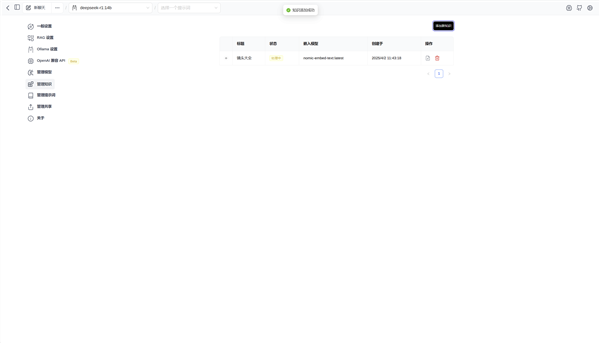
上传文件之后文本嵌入模型就会自动会文件进行处理,需要一小段时间。
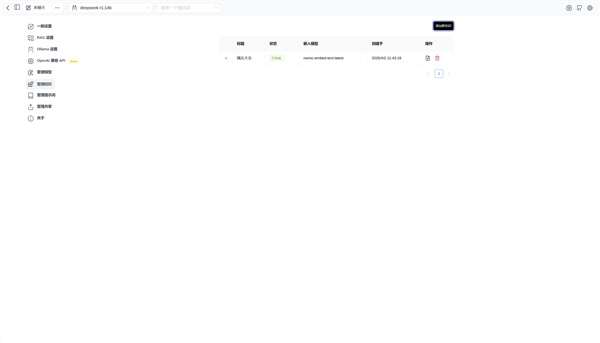
文本嵌入模型处理完毕之后,就可以开始使用知识库进行信息检索和查询了。
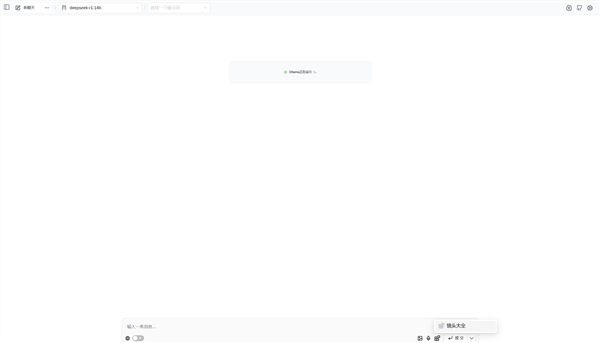
点击输入框中知识库的图标,就可以选择刚刚建立好的“镜头大全”知识库。
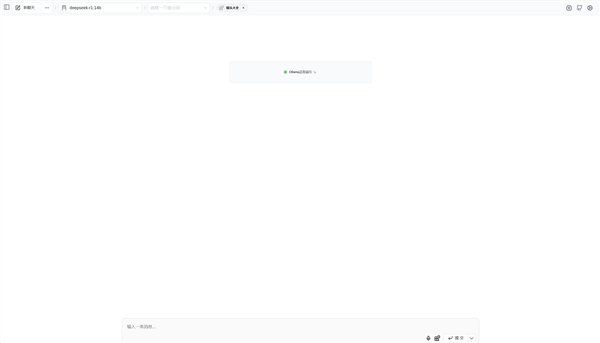
选择知识库之后,可以看到输入框中少了一些功能,上传图片和联网的标志隐藏了起来,在知识库中,是不能使用联网和识图功能的,但不影响知识库本身的功能使用。
屏幕上方可以看到“镜头大全”知识库已被读入,这时就可以使用Deepseek-R1:14B模型来检索知识库,Deepseek-R1:14B模型对用户提问和知识库内的语句理解和推理能力远超规模较小的模型。
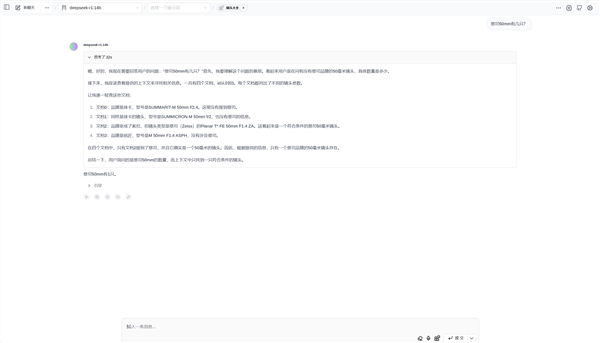
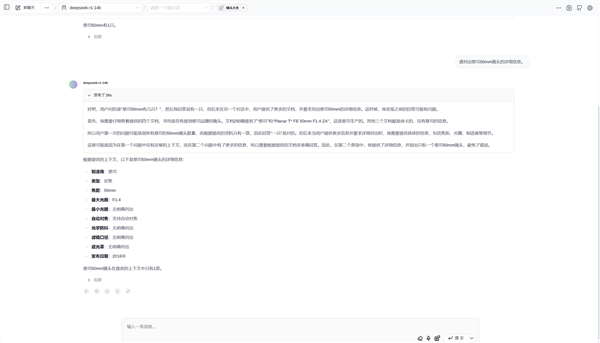
此时向Deepseek-R1:14B模型提问,它就会用上传的资料内容进行回答,比自己翻找表格更加方便快捷。
八、总结:轻薄本没有显卡一样能部署本地AI大模型 而且还很好用
Intel酷睿Ultra 9 285H处理器基于Arrow Lake架构,拥有6个性能核,8个能效核和2个低功耗能效核,一共16核心,但不支持超线程技术,所以总线程数也是16, 性能核最大睿频频率为5.4GHz,拥有24MB高速缓存。它内建Intel锐炫140T显卡,包含8个Xe核心,同时还内置NPU,能够提供高达13 TOPS的算力。CPU+GPU+NPU全平台总算力达到99 TOPS,为本地运行大模型提供了很好的支撑。AI PC并不是预装几个AI软件提供云服务就算AI PC了,如果只是购买云端AI算力服务来使用,那几年前的电脑甚至手机也一样能做到。AI PC最强大的地方就在于本地算力,购买了全新的AI PC,就拥有了这些算力,能陪着你走遍天涯海角,能在断网等环境下使用本地算力持续运行,这也是本地部署AI大模型的意义。

得益于Intel酷睿Ultra 9 285H处理器的强大性能和极高的能效,让轻薄本也能轻松在本地部署AI大模型,运行14B参数规模的Deepseek-R1大模型也不在话下。本地部署大模型,也是要根据实际用途来选择合适的模型来部署,现在开源的模型这么多,我们也不能想着直接部署最强的模型就能包打天下,也要根据实际用途选择来选择。我们为翻译服务选择了Qwen2.5:1.5B模型,看起来规模和Deepseek-R1:1.5B模型规模相当,但在翻译质量上差距十分明显,但如果是编程或者写作之类的需求的话,Deepseek-R1:14B模型才是更好的选择。Intel现在正在大力推广AI硬件,酷睿家族处理器的AI性能在一次次AI创新应用大赛中被深度发掘,Intel OpenVINO推理框架也越来越收到重视,轻薄本的AI性能也越来越好,即使没有显卡的AI PC,将来也会也会越来越好用。
相关阅读
评论
